Apartment Hunting with Python
I recently crossed the 9-month mark as a Chicago resident. The time has come for a big decision: renew my lease, or make the move to a new apartment?
I really like my current home. Two bedrooms, a back porch, a garage, and more grounded outlets than even a tech nerd like me could want. It’s in Little Italy, which is not a popular choice for Chicago young professionals, but is comfortable and has a decent set of restaurants. I suspect that a similar unit in a more “hip” neighborhood might be out of my price range. And my real office (as opposed to my extra bedroom, which has been serving in that capacity since I moved here) is a 10-minute bike ride away. The north side, home of many of those hip neighborhoods, would bring with it a commute at least twice as long.
On the other hand, my primary motivation in moving to a big city was exploration and experience. I wanted to get to know Chicago, particularly its neighborhoods. Moving would offer me a change of location, unlocking many new walkable or bikable destinations. Additionally, none of my friends live near my current apartment; most are in various parts of the northern neighborhoods, while I live somewhat south and west of the Loop (the downtown area of Chicago). Seeing most friends requires a 15+ minute drive or 30+ minute train ride.
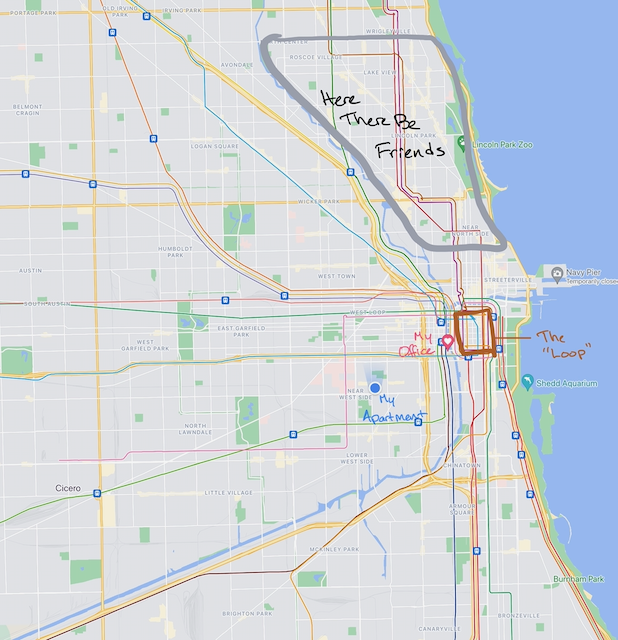
On the other other hand, I’ve never lived in my neighborhood during “normal” times, so I’m hardly in a position to render a judgment on it. I’ve recently discovered ultimate frisbee and basketball groups that meet nearby, and as a lover of pickup sports, I would love to attend multiple times a week. Finding groups here that I like and that don’t require a long commute is a big point in favor of my current home.
As you can see, I’m torn. There are pros and cons. Part of the trouble with decisions about moving is the uncertainty: yes, you tend to have a pretty good sense of how much you like your current domestic situation, but it’s hard to know how it compares to the great unknown of apartments you don’t live in.
Turning to Zillow
The easiest way to resolve some of this uncertainty is to systematically investigate apartments listings on a website like Zillow. Many questions boil down to some variant of “What combination of amenities can I get, in neighborhood X, at price point Y?”. For me, air conditioning, in-unit laundry, a parking spot, and some outdoor space (a deck or patio) are at the top of the amenity list. I want to know which of those I can get in an apartment within my budget, in each of the neighborhoods I’m considering. And – importantly – the apartments also have to meet a general standard of quality and attractiveness that I’m never going to be able to define in a search query.
This is admittedly a hard problem to build a nice user interface around. Zillow actually does a pretty good job: you can add filters to results using criteria like price range, neighborhood or geographic boundary, or set of amenities.
But it’s not quite the ideal way to understand my apartment options, for a few reasons:
-
There’s no easy way to keep track of which properties you’ve already seen. You can “heart” the ones you like, but units you’ve ruled out for one reason or another remain in the search results and on the interactive map. And since search result order seems to change, it’s almost impossible to conduct a thorough, exhaustive review of all options.
-
It’s hard to express your interrelated preferences. Zillow makes it easy to create a blanket filter (“rent must be below x”), but there’s no way to define something more nuanced. Maybe I’m willing to pay an extra $200 a month if the apartment has parking – sure, I can raise my maximum price and require the place have parking, but I can’t require the latter as a condition for the former. With location, it can be even more complicated; yes, I would be willing to consider a place outside of the neighborhood I want, but only if it were perfect in every other way.
-
While it’s not exactly a problem with the interface, the lack of a simple way to export data and save it means that you can’t just build your own spreadsheet of apartments – which would be a good answer to the first two issues. Maybe this lack of “data portability” is something that would irk only a programmer, but it’s frustrating.
Fortunately, a dose of that same programmer sensibility can help solve all three issues.
Web Scraping with Python
… is the title of an excellent O’Reilly book I finished recently. It’s also a solution to some of my frustrations with the Zillow website.
And if you came here looking for a technical article about Python, I promise you’ve found it at last. I’m not going to explain every aspect of the scraper I built; it’s a lot of code and makes use of some intermediate-level features of Python itself, like type hints and packaging. But I’ll walk through some of the interesting bits and try to keep the discussion at a level such that newcomers to web scraping should leave with a better understanding of how it works and how to get started. The only expectations for the reader, from here on out, is comfort with Python and a passing familiarity with HTML.
If you want to peruse the code yourself, you can find it here.
The Basics of “Scraping”
Using the requests library, it’s not hard to interact with the Zillow website (or most other sites) from Python.
The simplest way to do this is to send a “Get” request to www.zillow.com and save the content of its response.
>>> import requests
>>> response = requests.get('https://www.zillow.com')
>>> page_content = response.content
Unfortunately, printing the response’s content yields just a lot of HTML, which most humans aren’t going to be able to understand very well. And that’s where the BeautifulSoup library comes in – it helps you parse HTML by searching for certain tags or attributes.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(response.content, 'html.parser')
The resulting soup object supports a .find method that makes it fairly straightforward to look for certain things in the HTML.
For example, this code prints out the first image on the page.
>>> soup.find('img')
<img alt="Zillow" height="14" src="https://www.zillowstatic.com/static/logos/logo-65x14.png" width="65"/>
Of course, figuring out what elements of the page you want, and extracting information from those bits can be tricky. And we don’t even know what page we want to pull from yet! Certainly the Zillow home page isn’t going to automatically show Chicago apartments with in-unit laundry. Finding the right URL (which we sometimes call an “endpoint”) and determining how to parse it is 90% of the work, at least.
The URL
Scraping websites meant for humans can be a pain, but a bright spot is that we can use our human brain to find shortcuts. Programmatically entering a search on the Zillow homepage seems likely to be hard; we’d have to get the page, parse through it to find the searchbar, enter “Chicago” as our location, locate the amenities checklist (to select things like washer/dryer), and then submit that search. A lot of effort would go into that.
But a far more elegant approach is to just conduct the search ourselves and save the URL of the results page. Then, as long as our search includes any apartment that could possibly meet our criteria, we can collect them all and do our filters later in the process.
So that’s what I did: I manually searched Zillow for Chicago apartments in my price range and specified the amenities I wanted. Submitting that search took me to a page with a URL that looked like this:
https://www.zillow.com/chicago-il/rentals/?searchQueryState=%7B%22pagination%22%3A%20%7B%7D%2C%20%22mapBounds%22%3A%20%7B%22west%22%3A%20-88.09607811914063%2C%20%22east%22%3A%20-87.36823388085938%2C%20%22south%22%3A%2041.217142667058575%2C%20%22north%22%3A%2042.444992337648856%7D%2C%20%22regionSelection%22%3A%20%5B%7B%22regionId%22%3A%2017426%2C%20%22regionType%22%3A%206%7D%5D%2C%20%22isMapVisible%22%3A%20false%2C%20%22filterState%22%3A%20%7B%22fsba%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22fsbo%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22nc%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22fore%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22cmsn%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22auc%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22pmf%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22pf%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22fr%22%3A%20%7B%22value%22%3A%20true%7D%2C%20%22ah%22%3A%20%7B%22value%22%3A%20true%7D%2C%20%22mf%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22manu%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22land%22%3A%20%7B%22value%22%3A%20false%7D%2C%20%22beds%22%3A%20%7B%22min%22%3A%202%7D%2C%20%22mp%22%3A%20%7B%22max%22%3A%203000%7D%2C%20%22price%22%3A%20%7B%22max%22%3A%20890941%7D%2C%20%22lau%22%3A%20%7B%22value%22%3A%20true%7D%2C%20%22doz%22%3A%20%7B%22value%22%3A%20%227%22%7D%7D%2C%20%22isListVisible%22%3A%20true%7D
At this point, I had the URL I needed – I could ask for this page via Python and know that it would contain exactly the results I wanted. But I was curious about why there were some recognizable words like “mapBounds”, “regionID”, “value”, and “false” in that long string. Could this URL be encoding the parameters of my search somehow?
After some googling, I discovered the quote and unquote functions in urllib, which can convert regular strings to URL-safe versions (and vice versa).
from urllib.parse import unquote
unquote('https://www.zillow.com/chicago-il/rentals/?searchQueryState=%7B%22pagination%22%3A%20%7B%7D%2C%20%22mapBounds%22%3A%20%7B%22...')
> 'https://www.zillow.com/chicago-il/rentals//?searchQueryState={"pagination": {}, "mapBounds": {"west": -88.09607811914063, "east": -87.36823388085938, "south": 41.217142667058575, "north": 42.444992337648856}, "regionSelection": [{"regionId": 17426, "regionType": 6}], "isMapVisible": false, "filterState": {"fsba": {"value": false}, "fsbo": {"value": false}, "nc": {"value": false}, "fore": {"value": false}, "cmsn": {"value": false}, "auc": {"value": false}, "pmf": {"value": false}, "pf": {"value": false}, "fr": {"value": true}, "ah": {"value": true}, "mf": {"value": false}, "manu": {"value": false}, "land": {"value": false}, "beds": {"min": 2}, "mp": {"max": 3000}, "price": {"max": 890941}, "lau": {"value": true}, "doz": {"value": "7"}}, "isListVisible": true}'
Our URL is actually hiding a nested structure that represents our search query! That’s pretty cool.
Now I don’t know exactly what each parameter means in this case, but some are easy: "doz" is days on Zillow, which I required to be 7 or fewer.
"beds": {"min": 2} indicates that I specified 2+ bedrooms.
The best part is that now we can store the search as part of our Python code and construct the URL on the fly; we could even tweak our search parameters by just updating their value in the Python code.
from urllib.parse import quote as url_quote
import json
import requests
CHI_URL = "https://www.zillow.com/chicago-il/rentals/"
query_state = {
"pagination": {},
"mapBounds": {
"west": -88.09607811914063,
"east": -87.36823388085938,
"south": 41.217142667058575,
"north": 42.444992337648856,
},
"regionSelection": [{"regionId": 17426, "regionType": 6}],
"isMapVisible": False,
"filterState": {
"fsba": {"value": False},
"fsbo": {"value": False},
"nc": {"value": False},
"fore": {"value": False},
"cmsn": {"value": False},
"auc": {"value": False},
"pmf": {"value": False},
"pf": {"value": False},
"fr": {"value": True},
"ah": {"value": True},
"mf": {"value": False},
"manu": {"value": False},
"land": {"value": False},
# Here begin the params I understand: beds, price, laundry, days on Zillow.
"beds": {"min": 2},
"mp": {"max": 3000},
"price": {"max": 890941},
"lau": {"value": True},
"doz": {"value": "7"},
},
"isListVisible": True,
}
# Turn the dictionary into a URL-safe string.
formatted_q_state = url_quote(json.dumps(query_state))
# Combine that string with the base URL for Chicago apartments on Zillow.
final_url = f"{CHI_URL}/?searchQueryState={formatted_q_state}"
# Fetch the page.
response = requests.get(final_url)
The real code is here. It also has to deal with complications like believable browser headers, fetching multiple pages of results, and maintaining cookies in a “session” across all of those page requests. But if you’re just here for the basics, those are rabbit holes you can easily skip for now.
Parsing Search Results
So we know the URL that returns the properties we’re interested in, we know how to fetch pages as HTML, and we know (in principle) that we can parse those pages using BeautifulSoup. How do we actually do it?
Well, the bad news is that there’s a lot of tedious clicking around that goes into it. To start, I typically go to the page in my browser and right click on bits of text that I want my scraper to be able to find. The “Inspect Element” option brings up the page HTML in a separate pane and highlights what part of that code defines the element in question. In this case, I focused on parts of the page that contained information on price, rooms (beds/baths), and square footage.
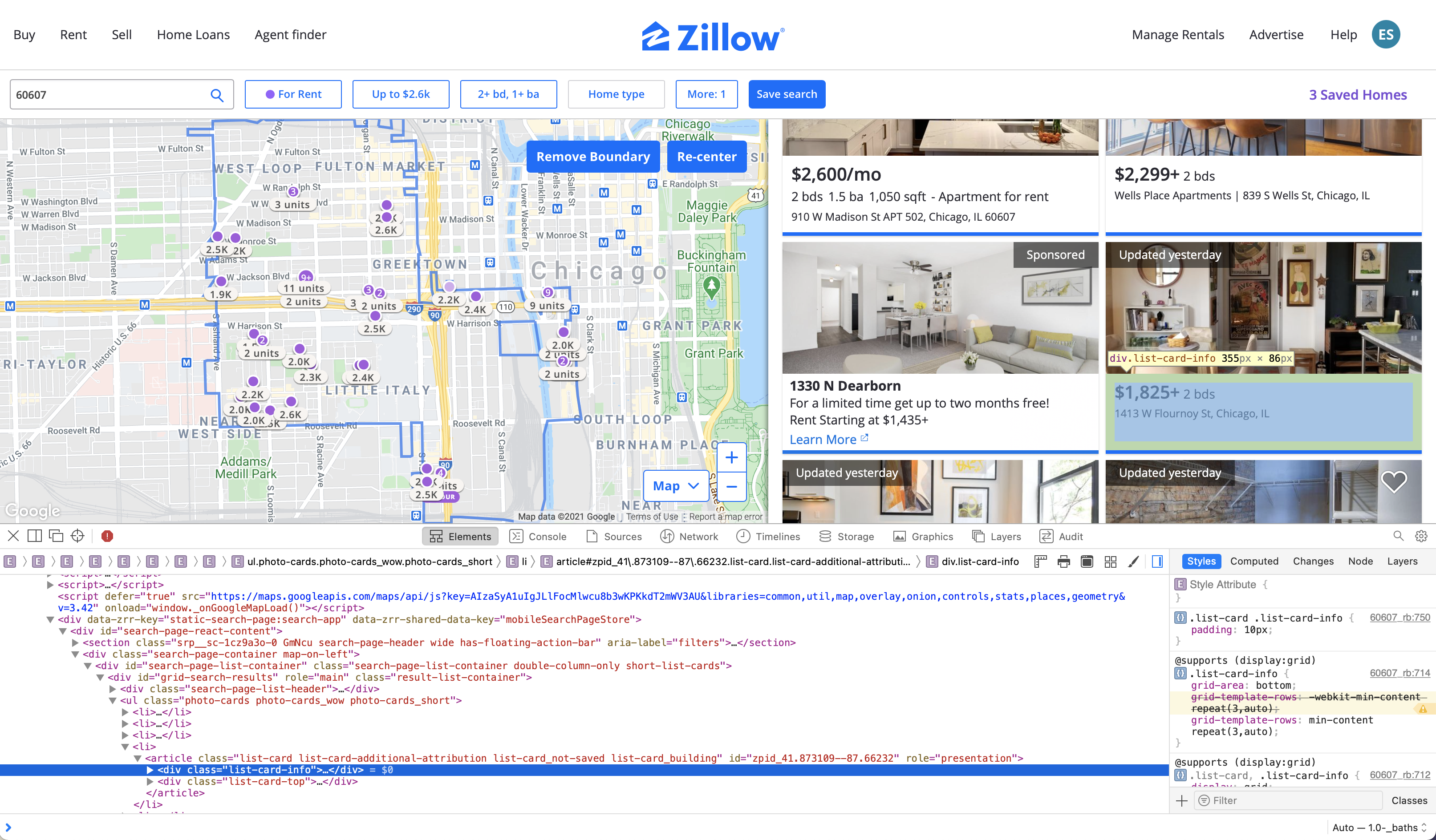
If you zoom in, you can see that I’ve selected the HTML code corresponding to the info for the apartment on the right.
<div class="list-card-info">...</div>
The ... indicates that there is more content between the opening and closing div tags, but it’s omitted here.
As enterprising web scrapers, we’re well on our way to getting the info we want.
It’s likely that all the search result properties are formatted similarly, so if we search the page for div elements that are of class list-card-info, we could potentially extract all the text inside and have basic attributes on each apartment.
We could print all the text inside each div with that class, using BeautifulSoup, like so:
# find_all returns *all* matching elements so we can loop over them.
for div in page.find_all("div", class_="list-card-info"):
print(div.text)
The actual code is quite a bit longer; I went deeper than the list-card-info and looked for more HTML elements within it, in order to sort out what text was about bedrooms vs price vs square footage (and used some regular expressions for that purpose as well).
I was also able to find data like latitude, longitude, and zip code for some properties.
But at a basic level, a lot of scraping is just about finding the element you want and extracting the text inside of it.
Saving Scraped Results
What do we do with all this information as we fetch it? One simple approach is to create a simple class representing an apartment unit.
from dataclasses import dataclass
@dataclass
class Property:
_id: str
price: int
address: str
lat: Optional[float]
lon: Optional[float]
zipcode: Optional[str]
url: str
details: List[str]
days_on_zillow: Optional[int]
json: Optional[Dict]
@dataclass is a Python decorator.
Decorators transform the thing they “decorate” in some way – in this case, it takes the fields I’ve defined and automatically builds an __init__ method for the class so I don’t have to.
The types are just for the reader (and for some static code analysis tools); dataclasses don’t provide any kind of automatic typechecking, just a way to set all the fields easily when the object is created.
So, if we’ve stored all these fields in variables already as we’ve scraped the page, we could instantiate a Property like so:
prop = Property(prop_id, price, address, lat, lon, zipcode, url, details, days_on_zillow, json)
Why bother storing properties using a class instead of just something like a list of lists (or list of tuples)? It both keeps us from accidentally creating a property with too many or too few fields (which could cause a mess later on), and it allows us to access individual attributes in a very readable way:
# Calculate average price of all properties
prices = [p.price for p in properties]
avg_price = sum(prices) / len(prices)
Best yet, Pandas DataFrames can be created from dataclasses without any extra fuss:
import pandas as pd
df = pd.DataFrame(properties)
This gives us a DataFrame with a row for each property and a column for each field.
So once we’ve scraped the page, turned properties into Propertys, and created a DataFrame, we can just save the DataFrame as a flat file – ideally with a name that denotes exactly when the data was pulled.
import datetime as dt
today = dt.date.today().strftime('%Y%m%d')
filename = f'raw_data/{today}.json'
df.to_json(filename)
A script that can do all these steps is perfectly suited to be run on a regular cadence.
Results are saved in a folder called raw_data/, named by the date of creation.
At this point, we’ve covered the basics of everything in the scrape submodule of my project.
Now we need to refine the data a little bit before we can analyze it.
Cleaning
The data cleaning process isn’t terribly interesting and fits entirely into one, 88-line file, so we won’t spend too much time on it. But the goal is to convert a raw data file and change the data to a form that’s easier to work with.
For example, many properties have a “details” field that contains strings like “2 bds, 1 ba, 1000 sqft”. But some are missing one piece (beds/baths/square footage). To break out the details column into separate columns containing numeric values for beds, baths, and square footage where possible, we can use regular expressions:
# Convert the "details" field into columns where possible.
bed_pattern = re.compile(r'(\d+) bds?')
bath_pattern = re.compile(r'(\d+(\.\d+)?) ba')
sqft_pattern = re.compile(r'(\d+(,\d+)?) sqft')
def extract_bed_bath_sqft(details):
beds = baths = sqft = None
for element in details:
# A great chance to try out the new walrus operator!
if m := bed_pattern.search(element):
beds = float(m.group(1))
elif m := bath_pattern.search(element):
baths = float(m.group(1))
elif m := sqft_pattern.search(element):
sqft = m.group(1).replace(',', '')
sqft = int(sqft)
return beds, baths, sqft
detail_cols = df.details.apply(lambda d: pd.Series(extract_bed_bath_sqft(d)))
df['beds'] = detail_cols[0]
df['baths'] = detail_cols[1]
df['sqft'] = detail_cols[2]
df = df.drop('details', axis=1)
Similarly, we look for clues in the URL as to whether this is a single unit or part of a larger complex. We drop duplicate records, and then add a special new field – the distance from a point that I consider a particularly prime location.
Once we’ve finished our cleanup, we save the updated DataFrame to a clean_data/ folder.
Analysis
If everything has gone according to plan, at this point our scraping program should have collected and saved information on promising properties: things like price, bedrooms, square footage, location, and more. You can see the final analysis notebook here.
To get started, we can open up all those files at once and merge them together into a single DataFrame using a combination of Pandas’ concat function and the Path class from the built-in pathlib library.
from pathlib import Path
import pandas as pd
# Use a glob pattern to pull *all* json files in the clean_data/ folder.
data_files = Path('clean_data').glob('*.json')
df = pd.concat(pd.read_json(filename) for filename in data_files)
I spent a little bit of time creating maps of the property locations, but the real crux of this project was devising a way to rank all these properties – after all, to this point we haven’t really learned anything new about potential apartments, just saved data about them in a flat file (which is harder to peruse than the Zillow website!).
But if we could score the properties in a useful way, we could just pull out the ones with the highest scores. Technically speaking, doing this is pretty simple: just write a function that takes in a row, looks at the fields you care about, and returns a number representing how promising the apartment is. The tricky part is figuring out how to describe your preferences in Python code. But it’s hardly insurmountable!
I decided that the information I had mostly fell into three categories: price, size, and location. Total quality is really a (weighted) combination of how good an apartment is on each of those dimensions. As a function, it looks something like this:
def total_score(row):
# Take a row representing a property and assign it a score,
# based on how much I'll like it.
p = PRICE_SCORE_WT * row['price_score']
l = LOC_SCORE_WT * row['loc_score']
sq = SQFT_SCORE_WT * row['sqft_score']
return p + l + sq
Now we need to determine the price, location, and size scores, along with the relative weighting of each. But the problem is much more tractable now. I won’t bore you with my specific implementations, but:
- To score location, I ranked the zipcodes in Chicago by how much I like the area.
- To score square footage, I heavily penalized apartments that fell below what I considered the minimum acceptable size, and then gave more points for larger places, with diminishing returns.
- To score for price, I established a range of minimum reasonable and maximum acceptable rent, and then scored based on where the property fell in that range.
Creating these scores, and the total score from them, is then pretty simple:
df['loc_score'] = df.apply(loc_score, axis=1)
df['sqft_score'] = df.apply(sqft_score, axis=1)
df['price_score'] = df.apply(price_score, axis=1)
df['total_score'] = df.apply(total_score, axis=1)
And the highest-ranked properties can be pulled with:
promising = df.sort_values('total_score', ascending=False)
promising.head()
Up to this point, I’d been using a naive guess at weights for price, size, and location. But with a ranking, I was able to decide if my algorithm was biased too much toward one of those aspects. Indeed, I ended up tweaking the weights and rerunning several times before being happy with my results. As I went, I kept track of the distributions of scores.
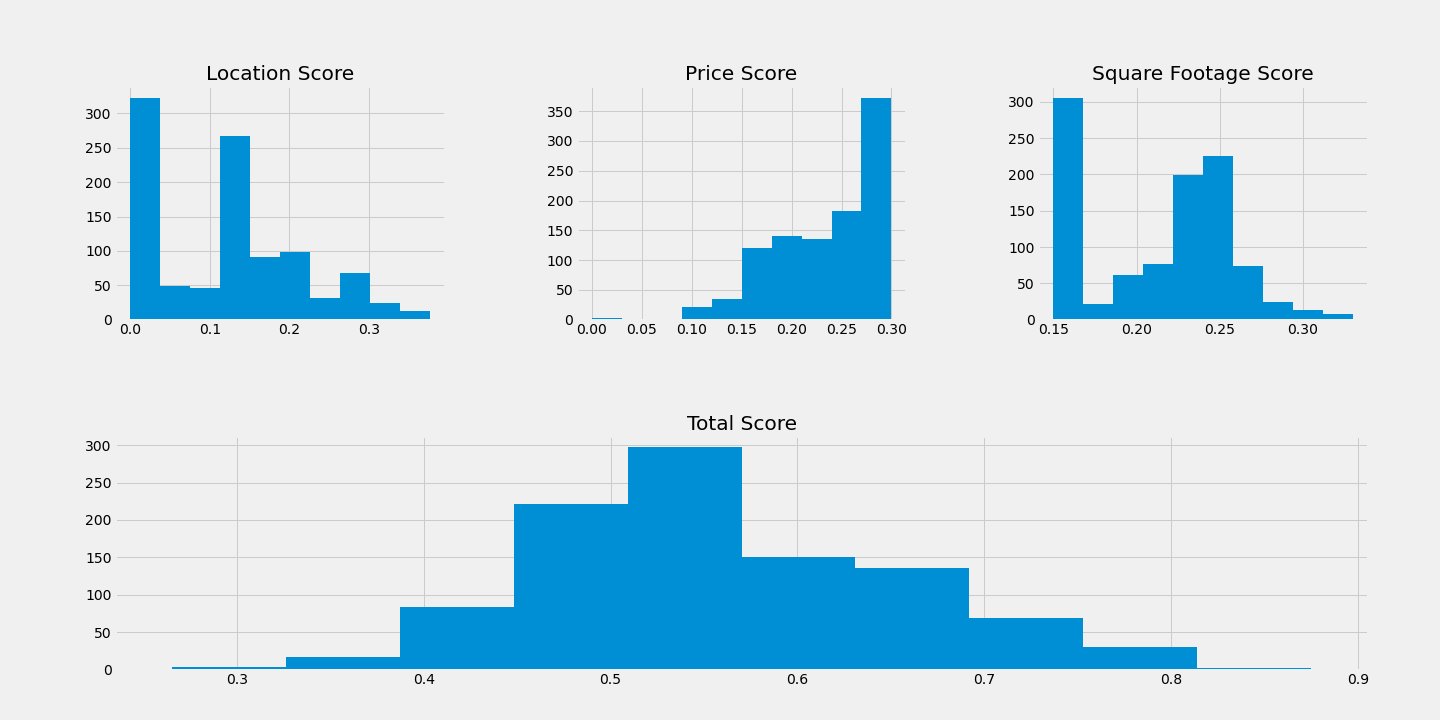
I also looked at the distribution of total score by zip code, and plotted the scores on a map to see where my preferred properties were clustered. But most importantly, I took my rankings and was able to look through them to get a sense of my other options throughout the city.

Epilogue
In the end, I settled on staying in my current place.
This project was really more about learning than making life decisions. My Zillow scraper didn’t find many units that I’d consider as desirable as my current place, but at the same time, I’m well aware that there are many hard-to-quantify aspects of apartments that my code wasn’t able to gather. Ultimately I just decided that the good things about my apartment, coupled with an interest in seeing my neighborhood as it comes back to life post-Coronavirus, were enough to keep me here.
There were a lot of things I omitted from this article for simplicity, but we covered most of the interesting and applicable bits. Some things, like adding type hints and packaging the code, are nice for polishing up a project but hardly required to get started. If you were able to follow along, there’s no reason you couldn’t start building your own scraper.
Special thanks to Zillow, for providing a fantastic apartment-hunting website, and to Max Bade, author of the post from which I got the headers for my HTTP requests. Most importantly, I can’t recommend highly enough the phenomenal Web Scraping with Python by Ryan Mitchell.
I hope you leave this article feeling like you got something useful out of it; I would like to write pieces like this more regularly, and would greatly appreciate feedback on this one to help me shape my future writing. If you have thoughts to share, you can find me on Twitter (@eswan18) or email me ([email protected]).